Chances are you heard that multiprocessing in Python is hard. That it takes time and, actually, don’t even try because there’s something like global interpreter lock (GIL), so it isn’t even true parallel execution. Well, GIL is true, but the rest is a lie. Multiprocessing in Python is rather easy.
One doesn’t have to look far to find nice introductions into processing in Python [link1, link2]. These are great and I do recommend reading on them. Even first Google result page should return some comprehensible tutorials. However, what I was missing from these tutorials is some information about handling processing within class.
Multiprocessing in Python is flexible. You can either define Processes and orchestrate them as you wishes, or use one of excellent methods herding Pool of processes. By default Pool assumes number of processes to be equal to number of CPU cores, but you can change it by passing processes parameter. Main methods included in Pool are apply and map, which let you run process with arbitrary arguments or execute parallel map, respectively. There are also asynchronous versions of these, i.e. apply_asyncand map_async.
Quick example:
from multiprocessing import Pool
def power(x, n=10):
return x**n
pool = Pool()
pow10 = pool.map(power, range(10,20))
print(pow10)
[10000000000, 25937424601, 61917364224, 137858491849, 289254654976, 576650390625, 1099511627776, 2015993900449, 3570467226624, 6131066257801]
Simple, right? Yes, this is all what’s needed. Now, go and use multiprocessing!
Actually, before you leave to follow your dreams there’s a small caveat to this. When executing processes Python first pickles these methods. This create a bottleneck as only objects that are pickle will be passed to processes. Moreover, Pool doesn’t allow to parallelize objects that refer to the instance of pool which runs them. It sounds convoluted so let me exemplify this:
from multiprocessing import Pool
class BigPow:
def __init__(self, n=10):
self.pool = Pool()
self.n = n
def pow(self, x):
return x**self.n
def run(self, args):
#pows = self.pool.map(ext_pow, args)
pows = self.pool.map(self.pow, args)
return sum(pows)
def ext_pow(x):
return x**10
if __name__ == "__main__":
big_pow = BigPow(n=10)
pow_sum = big_pow.run(range(20))
print(pow_sum)
Code above doesn’t work, unless we replace self.pow with ext_pow. This is because self contains pool instance. We can remove that through removing pool just before pickling through __getstate__ (there’s complimentary function __setstate__ to process after depickling).
from multiprocessing import Pool
class BigPow:
def __init__(self, n=10):
self.pool = Pool()
self.n = n
def pow(self, x):
return x**self.n
def run(self, args):
pows = self.pool.map(self.pow, args)
return sum(pows)
def __getstate__(self):
self_dict = self.__dict__.copy()
del self_dict['pool']
return self_dict
if __name__ == "__main__":
big_pow = BigPow(n=10)
pow_sum = big_pow.run(range(20))
print(pow_sum)
This is good, but sometimes you’ll get an error stating something like “PicklingError: Can’t pickle : attribute lookup __builtin__.instancemethod failed”. In such case you have to update registry for pickle on what to actually goes into pickling.
from multiprocessing import Pool
#######################################
import sys
import types
#Difference between Python3 and 2
if sys.version_info[0] < 3:
import copy_reg as copyreg
else:
import copyreg
def _pickle_method(m):
class_self = m.im_class if m.im_self is None else m.im_self
return getattr, (class_self, m.im_func.func_name)
copyreg.pickle(types.MethodType, _pickle_method)
#######################################
class BigPow:
def __init__(self, n=10):
self.pool = Pool()
self.n = n
def pow(self, x):
return x**self.n
def run(self, args):
pows = self.pool.map(self.pow, args)
return sum(pows)
def __getstate__(self):
self_dict = self.__dict__.copy()
del self_dict['pool']
return self_dict
if __name__ == "__main__":
big_pow = BigPow(n=10)
pow_sum = big_pow.run(range(20))
print(pow_sum)
Yes, this is all because of Pickle. What can you do with it? In a sense, not much, as it’s the default battery-included solution. On the other, pickle is generally slow and now community standard seems to be dill. It would be nice if something was using dill instead of pickle. Right? Well, we are in luck because pathos does exactly that. It has similar interface to multiprocessing is it’s also easy to use. Personally I’m Ok with multiprocessing, as I like not to import too much, but this is a good sign that there are developments towards more flexible solutions.
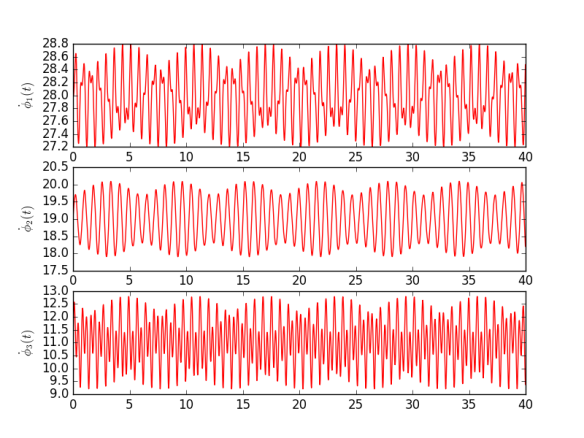
 with distinct oscillators, i.e.
with distinct oscillators, i.e.  .
. .
. is defined as
is defined as 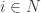 is defined by
is defined by  , where the summation is over all others oscillators. Note that one can leave coupling with itself, because in such case
, where the summation is over all others oscillators. Note that one can leave coupling with itself, because in such case  , thus it doesn’t input anything into the final solution.
, thus it doesn’t input anything into the final solution. and
and  . In general Kuramoto model of order
. In general Kuramoto model of order  would describe
would describe  .
.


 , initial velocities
, initial velocities  , acceleration ratio
, acceleration ratio  and influence variable of the best global
and influence variable of the best global 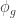 and the best local
and the best local  parameters. One also has to declare how many particles will be used and how many generations is the limit (or what is acceptable error of solution).
parameters. One also has to declare how many particles will be used and how many generations is the limit (or what is acceptable error of solution). + U(-0.025,0.025)$, where
+ U(-0.025,0.025)$, where  is a random noise from unitary [a, b] distribution. Fitted function is
is a random noise from unitary [a, b] distribution. Fitted function is  , thus the expected values are P={4, 4, pi/2, 3}. See figure for fitted curve below. Obtained values are P = { 4.61487992 3.96829528 1.60951687 3.43047877} which are not far off. I am aware that my example is a bit to simple for such powerful search technique, but it is just a quick example.
, thus the expected values are P={4, 4, pi/2, 3}. See figure for fitted curve below. Obtained values are P = { 4.61487992 3.96829528 1.60951687 3.43047877} which are not far off. I am aware that my example is a bit to simple for such powerful search technique, but it is just a quick example.
 coupled ODEs and seeing how fast it’s performed makes me simply happy. Really simple!
coupled ODEs and seeing how fast it’s performed makes me simply happy. Really simple! , but for copying purposes I left it in long form.
, but for copying purposes I left it in long form. , i]'[t] == Subscript[w, i] + Sum[Subscript[k, i, j] Sin[Subscript[
, i]'[t] == Subscript[w, i] + Sum[Subscript[k, i, j] Sin[Subscript[
